9.2 KiB
2. Challenges
A challenge within the context of TIG is a computational problem adapted as one of the proof-of-works in OPoW. Presently, TIG features three challenges: boolean satisfiability, vehicle routing, and the knapsack problem. Over the coming year, an additional seven challenges from domains such as AI, cryptography, biomedical research, and climate science will be phased in.
Beyond this initial set of ten challenges, TIG's roadmap includes the establishment of a scientific committee tasked with sourcing diverse computational problems.
This chapter covers the following topics:
- What is the relation between Benchmarkers and Challenges
- How real world computational problems are adapted for proof-of-work
- Regulation of the network's computational load for verifying solutions
2.1. Challenge Instances & Solutions
A challenge constitutes a computational problem from which instances can be deterministically pseudo-randomly generated given a seed and difficulty. Benchmarkers iterate over nonces to generate seeds and subsequently produce challenge instances to compute solutions using an algorithm.
Each challenge also stipulates the method for verifying whether a "solution" indeed solves a challenge instance. Since challenge instances are deterministic, anyone can verify the validity of solutions submitted by Benchmarkers.
Notes:
-
The minimum difficulty of each challenge ensures a minimum of 10^15 unique instances, with even more as difficulty increases.
-
Some instances may lack a solution, while others may possess multiple solutions.
-
Algorithms are not guaranteed to find a solution.
2.2. Adapting Real World Computational Problems
Computational problems with scientific or technological applications typically feature multiple difficulty parameters. These parameters may control factors such as the accuracy threshold for a solution and the size of the challenge instance.
For example, TIG's version of the Capacitated Vehicle Routing Problem (CVRP) incorporates two difficulty parameters: the number of customers (nodes) and the factor by which a solution's total distance must surpass the baseline value.
TIG's inclusion of multiple difficulty parameters in proof-of-work sets it apart from other proof-of-work cryptocurrencies, necessitating innovative mechanisms to address two key issues:
- Valuing solutions of varying difficulties for comparison
- How difficulty with multiple parameters should be adjusted
Notes:
-
Difficulty parameters are always integers for reproducibility, with fixed-point numbers used if decimals are necessary.
-
The expected computational cost to compute a solution rises monotonically with difficulty.
2.2.1. Pareto Frontiers & Qualifiers
The issue of valuing solutions of different difficulties can be deconstructed into three sub-issues:
-
There is no explicit value function that can "fairly" flatten difficulties onto a single dimension without introducing bias
-
Setting a single difficulty will avoid this issue, but will excessively limit the scope of innovation for algorithms and hardware
-
Assigning the same value to solutions no matter their difficulty would lead to Benchmarkers "spamming" solutions at the easiest difficulty
The key insight behind TIG's Pareto frontiers mechanism (described below) is that the value function does not have to be explicit, but rather can be fluidly discoverable by Benchmarkers in a decentralised setting by allowing them to strike a balance between the difficulty they select and the number of solutions they can compute.
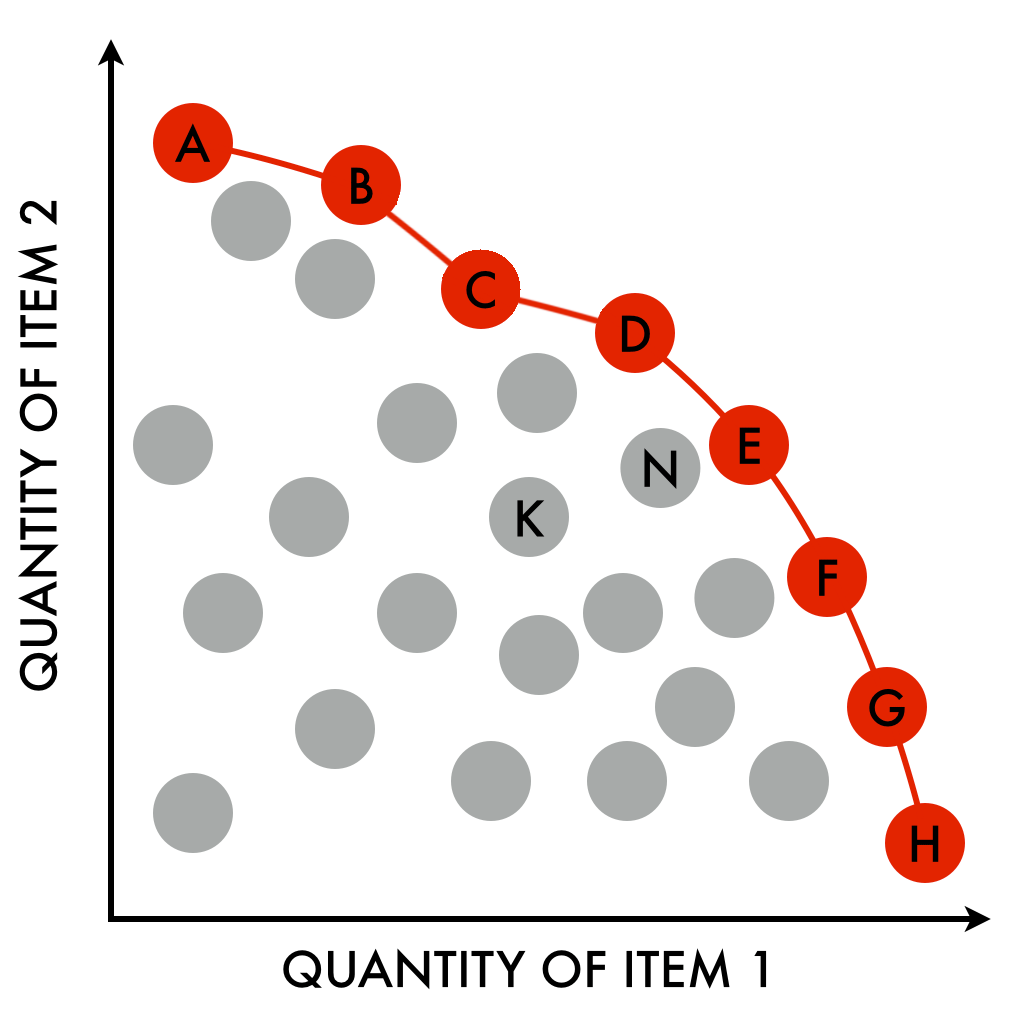
Figure: The red line is an example of a Pareto frontier. Sourced from wikipedia
This emergent value function is naturally discovered as Benchmarkers, each guided by their unique value function, consistently select difficulties they perceive as offering the highest value. This process allows them to exploit inefficiencies until they converge upon a set of difficulties where no further inefficiencies remain to be exploited; in other words, staying at the same difficulties becomes more efficient, while increasing or decreasing would be inefficient.
Changes such as Benchmarkers going online/offline, availability of more performant hardware/algorithms, etc will disrupt this equilibrium, leading to a new emergent value function being discovered.
The Pareto frontiers mechanism works as follows:
-
Plot the difficulties for all active solutions or benchmarks.
-
Identify the hardest difficulties based on the Pareto frontier and designate their solutions as qualifiers.
-
Update the total number of qualifying solutions.
-
If the total number of qualifiers is below a threshold (currently set to
1000), repeat the process.
Notes:
-
Qualifiers for each challenge are determined every block.
-
Only qualifiers are utilised to determine a Benchmarker's influence and an Algorithm's adoption, earning the respective Benchmarker and Innovator a share of the block rewards.
-
The total number of qualifiers may be over the threshold. For example, if the first frontier has
400solutions, the second frontier has900solutions, then there are1300qualifiers.
2.2.2. Difficulty Adjustment
Every block, the qualifiers for a challenge dictate its difficulty range. Benchmarkers, when initiating a new benchmark, must reference a specific challenge and block in their benchmark settings before selecting a difficulty within the challenge's difficulty range.
At a high level, a challenge's difficulty range is determined as follows:
-
From the qualifiers, filter out the easiest difficulties based on the Pareto frontier to establish the base frontier.
-
Calculate a difficulty multiplier (capped to
2.0)difficulty\ multiplier = \frac{number\ of\ qualifiers}{threshold\ number\ of\ qualifiers}- e.g. if there are
1500qualifiers and the threshold is1000, the multiplier is1500/1000 = 1.5
-
Multiply the base frontier by the difficulty multiplier to determine the upper or lower bound.
- If multiplier > 1, base frontier is the lower bound
- If multiplier < 1, base frontier is the upper bound
The following Benchmarker behaviour is expected:
-
When number of qualifiers is higher than threshold: Benchmarkers will naturally select harder and harder difficulties so that their solutions stay on the frontiers for as long as possible, as only qualifiers count towards influence and share in block rewards.
-
When number of qualifiers is equal to threshold: Benchmarkers will stay at the same difficulty
-
When number of qualifiers is lower than threshold: Benchmarkers will naturally select easier and easier difficulties to compute more solutions which will be qualifiers.
2.3. Regulating Verification Load
Verification of solutions constitutes almost the entirety of the computation load for TIG's network. In addition to probabilistic verification which drastically reduces the number of solutions that require verification, TIG employs a solution signature threshold mechanism to regulate the rate of solutions and the verification load of each solution.
2.3.1. Solution Signature
A solution signature is a unique identifier for each solution derived from hashing the solution and its runtime signature. To be considered valid, this signature must fall below a dynamically adjusted threshold.
Each challenge possesses its own dynamically adjusted solution signature threshold which starts at 100% and can be adjusted by a maximum of 0.25% per block. This percentage reflects the probability of a solution being valid.
Lowering the threshold has the effect of reducing the probability that any given solution will be valid, thereby decreasing the overall solution rate. As a result, the number of qualifiers, and subsequently the difficulty range of the challenge, will also decrease. Increasing the threshold has the opposite effect.
There are 2 feedback loops which adjusts the threshold:
-
Target fuel consumption (currently disabled). The execution of an algorithm is performed through a WASM Virtual Machine which tracks "fuel consumption", a proxy for the real runtime of the algorithm. Fuel consumption is deterministic and is submitted by Benchmarkers when submitting solutions.
Another motivation for targeting a specific fuel consumption is to maintain a fair and decentralised system. If the runtime approaches the lifespan of a solution, raw speed (as opposed to efficiency) would become the dominant factor, potentially giving a significant advantage to hardware (such as supercomputers) that prioritises speed over efficiency.
-
Target solutions rate. Solutions rate is determined every block based on mempool proofs that are being confirmed. (Each proof is associated with a benchmark, containing a number of solutions).
Spikes in solutions rate can occur when there is a sudden surge of new Benchmarkers/compute power coming online. If left unregulated, the difficulty should eventually rise such that the solution rate settles to an equilibrium rate, but this may take a prolonged period causing a strain on the network from the large verification load. To smooth out the verification load, TIG targets a specific solutions rate.